如何用爬虫抓取股市数据并生成分析报表(爬虫爬取股票数据)
这篇文章由爱心网友给大家分享下如何用爬虫抓取股市数据并生成分析报表,以及爬虫爬取股票数据对应的知识点,希望对大家能有所帮助。
用Python爬虫可以爬过去的网站吗?
是的,Python可以实现自动抓取互联网上的新闻并更新到网站。Python有很多强大的网络爬虫库,如BeautifulSoup、Scrapy等,可以帮助您实现网页内容的自动抓取。
不能。爬网站属于爬墙,是计算机中的专业语言,是一种违法行为,因此python不能爬国外的网站。Python是一种跨平台的计算机程序设计语言,是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
用python爬取网站数据方法步骤如下:首先要明确想要爬取的目标。对于网页源信息的爬取首先要获取url,然后定位的目标内容。先使用基础for循环生成的url信息。
你可以用爬虫爬图片,爬取视频等等你想要爬取的数据,只要你能通过浏览器访问的数据都可以通过爬虫获取。
如何用用网络爬虫代码爬取任意网站的任意一段文字?
1、先分析网站内容,红色部分即是网站文章内容div。
2、Java网络爬虫可以通过使用第三方库或自行编写代码来实现。以下是一种常见的实现方式: 导入相关的库:在Java项目中,可以使用Jsoup等第三方库来处理HTML页面,获取页面内容。
3、爬取一个url:解析内容:存本地文件:代码说明:需要修改获取requests请求头的authorization。需要修改你的文件存储路径。
网页数据采集是什么,有什么用,如何实现的?
1、确定采集目标:首先要明确自己需要采集哪些网页数据。可以是某个特定网站的所有页面,也可以是特定关键词的搜索结果页面。选择采集工具:根据采集目标的不同,选择合适的采集工具。
2、网站采集是一种常见的网络技术,也称为网站抓取或网站爬虫。它的作用是用程序自动抓取互联网上的信息,将数据进行提取、加工、存储和分析,实现对互联网信息的快速获取和处理。
3、网页数据采集:简单的说获得网页上一些自己感兴趣的数据。
如何“爬数据”?
拿爬取网站数据分析:用浏览器开发者工具的Network功能分析对应的数据接口或者查看源代码写出相应的正则表达式去匹配相关数据 将步骤一分析出来的结果或者正则用脚本语言模拟请求,提取关键数据。
从网站抓取数据有多种方法,以下是三种最佳方法: 使用API接口:许多网站提供API接口,允许开发者通过API获取网站上的数据。使用API接口可以直接从网站的数据库中获取数据,速度快且准确。
简单笼统的说,爬数据搞定以下几个部分,就可以小打小闹一下了。指定URL的模式,比如知乎问题的URL为http://zhihu.com/question/xxxx,然后抓取html的内容就可以了。
如果你是小白的话可以找一个爬虫软件也是可以滴,小编用前嗅比较多,有需要自己百度,他们官网有免费版本。污染数据网站:这个就要根据你的数据需求来找了。
如何自学python爬虫?
1、学习Python基础:首先,你需要学习Python的基础知识,包括语法、数据类型、控制流等。有许多在线教程和书籍可以帮助你入门,例如《PythonCrashCourse》或Codecademy的Python课程。
2、阶段四:WEB框架开发 Python全栈开发与人工智能之WEB框架开发学习内容包括:Django框架基础、Django框架进阶、BBSBlog实战项目开发、缓存和队列中间件、Flask框架学习、Tornado框架学习、RestfulAPI等。
3、第一阶段:Python基础与Linux数据库 这是Python的入门阶段,也是帮助零基础学员打好基础的重要阶段。
如何爬虫网页数据
1、基于API接口的数据采集:许多网站提供API接口来提供数据访问服务,网络爬虫可以通过调用API接口获取数据。与直接采集Web页面相比,通过API接口获取数据更为高效和稳定。
2、以下是网络爬虫的入门步骤: 确定采集目标:首先需要明确你想要采集的数据是什么,以及数据来源是哪个网站或网页。 学习HTML和XPath:了解HTML和XPath的基本知识,这是进行网页解析和数据提取的基础。
3、安装必要的库 为了编写爬虫,你需要安装一些Python库,例如requests、BeautifulSoup和lxml等。你可以使用pip install命令来安装这些库。抓取网页数据 主要通过requests库发送HTTP请求,获取网页响应的HTML内容。
关于如何用爬虫抓取股市数据并生成分析报表和爬虫爬取股票数据的介绍到此就结束了,不知道你从中找到你需要的信息了吗?如果你还想了解更多这方面的信息,记得收藏关注本站。
本站文章为热心网友投稿,如果您觉得不错欢迎转载,转载请保留链接。网址:http://www.xzz5.com/news_66896
同花顺股票如何绑定证券账户(同花顺app绑定证券账户)
股票庄家为什么要压盘(庄家为什么一直压着股价)
新三板利通液压怎么样(新三板利通液压怎么样啊)
八佰伴股票,八佰伴是什么店?(八佰伴是上市公司吗)
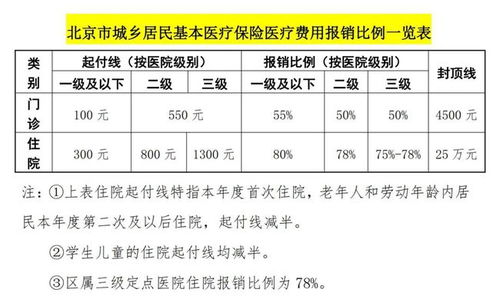
如何查找同期跌幅较大股票(同比跌幅怎么算)
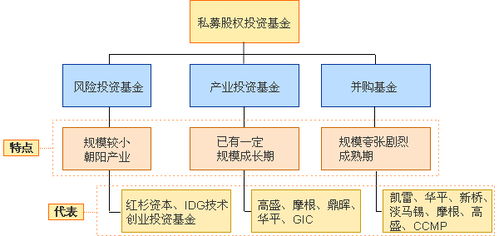
恒力集团股票(恒力集团股票市值值多少钱)
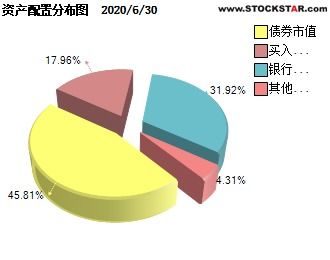
希土永磁股票(希土永磁股票行情)

股票为什么昨收与今开的价格不一样(股票昨收和今开)
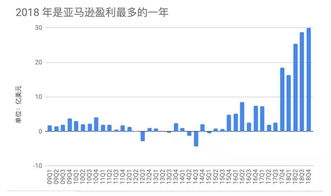
新手怎样炒股和炒基金(新手炒基金好还是股票好)
大湾区医疗设备股票有哪些(大湾区药械)
解惑可转债被强制赎回会影响股票吗震惊了(可转债强制赎回后股价走势)
怎么看出一只股票属于哪个指数(怎么看一只股票属于什么概念)
云安全股票怎么样(云信息安全股票)
如何看股票走势图南方财富(怎么样才能看懂股票走势)
什么基金定投比较好?(什么基金最适合定投)

最具潜力的股票有哪些?(最具潜力的股票有哪些龙头)
关注财经知识